
Word segmentation, part-of-speech tagging, and named entity recognition based on domain data and user behavior. It is used to locate basic language elements, eliminate ambiguities, and support the accurate understanding of natural language.
“"How long does it take to send a parcel from Keyuan North Road, Science and Technology Park, Nanshan District, Shenzhen to Jing'an District, Shanghai?" ”
Analysis Results:
From (preposition)|Shenzhen (place name)|Nanshan District (place name)|Keyuan North Road, Science and Technology Park (place name)|send to (verb)|Shanghai (place name)|Jing'an District (place name), approximately (adverb) how long (time noun)?


Relying on massive open-source data on the Internet and high-quality dialogue data generated by Feiyu's intelligent voice system, it uses deep learning technology to realize text computability through word vectorization, enabling the platform's semantic mining, similarity calculation and other applications.
Through training, words in the language vocabulary are mapped to fixed-length vectors. All word vectors in the vocabulary form a vector space, and each word is a point in this word vector space. This method realizes text computability.
For Example:
In the domain, the cosine result of the word vectors of two words with very similar meanings is high. For example 1, the meanings of the two words 'express' and 'parcel' are very similar; the general cosine value is >0.7, and the domain-specific cosine value is >0.9, proving that the distance between the two words is close.
For example 2, the meanings of the two words 'ship' and 'sign for' are not very similar; the cosine value is relatively low, indicating that the distance between the two words is far.
Calculates the semantic similarity between two words based on lexical analysis and word vector representation, helping to quickly realize problem retrieval, answer recommendation, and ranking applications.
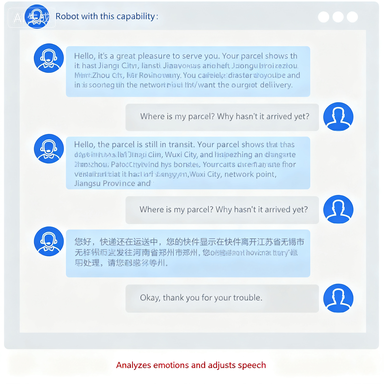
During the user dialogue process, it combines the acoustic features of the customer's dialogue and the emotional features contained in the text to help enterprises fully grasp product experience and monitor customer service quality.

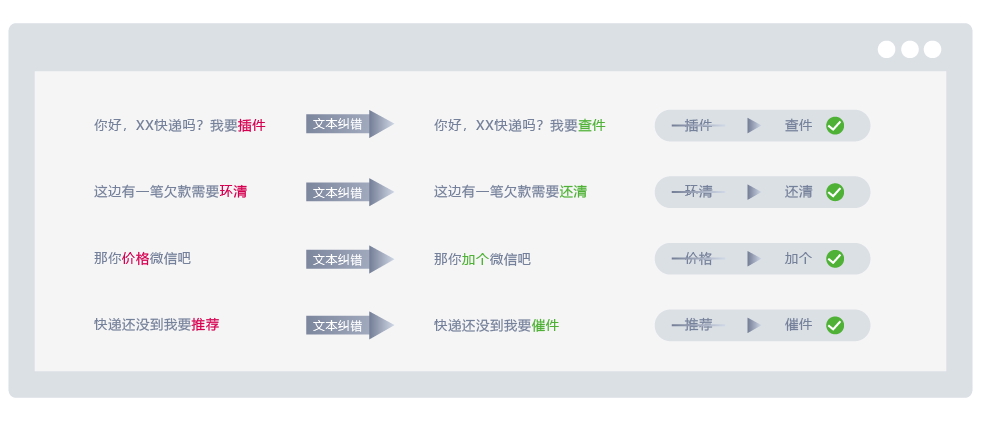
In the scenario of making calls with customers, due to various environmental and phone signal factors, the accuracy of speech recognition is much lower than that in the laboratory. Speech recognition converted into text often has wrong segments. Error prompts and corrected results are provided, which are of great help to the understanding of customer intentions.
Error correction method
During dialogue, customers' words are often misrecognized by speech recognition. By analyzing the form and characteristics of massive dialogue content, the results of speech recognition can be automatically corrected, and then answers more in line with user needs can be provided, effectively identifying the impact of errors on users' real needs.
For the business data of express logistics industry scenarios such as parcel tracking, delivery urging, consultation, order placement, delivery, and receipt, it builds an intelligent knowledge graph for customers' structured, semi-structured, and unstructured multi-source heterogeneous data. It achieves better results in text error correction, context association, and intent reasoning, greatly optimizing the ability of phone robots to understand customers' real intentions.

Specially trained for VoIP voice signals and optimized through scenario-based recognition. It provides speech recognition solutions for industries such as express logistics and manufacturing, with an accuracy rate of over 85%.
Converts customers' speech to text in real time while they are speaking. It adopts streaming transmission, and the response speed is faster than converting from recordings (response speed increased by at least 20%).
Enterprises can provide enterprise-related recordings and keyword information to train exclusive recognition models. The more corpora submitted, the more obvious the improvement of speech recognition effect.

Provides three modes: real-person voice library, full machine-synthesized voice library, and mixed voice library of real-person and machine synthesis. Customization is available to meet the application needs of different industries.
The conventional method is to synthesize text into voice first, then play it through the voice platform. Synthesizing longer text into voice takes about 1 second. Feiyu adopts streaming synthesis to convert and play simultaneously. No matter how long the text is, it starts playing within 200ms~300ms, greatly improving speed and fluency.

 About Us
About Us